# 简介
chunks以及它引入的modules本质上是通过webpack处理module之间的父子关系所做的关联。在webpack4以前,我们使用CommonsChunkPlugin插件来避免依赖的重复打包,但是这样很难进行更深一步的优化。
从webpack4开始,CommonsChunkPlugin被移除,新增了optimization.splitChunks和optimization.runtimeChunk选项。
译:重心其实就是内置一个配置项,可以把符合指定规则的module提取为chunk,官方说新的方法贼好用(反正在我研究明白之前真没觉得好用,文档实在是不友好,有些概念不好理解)
# Defaults
SplitChunksPlugin对大多数用户来说都更加好用。
默认配置下,它只会影响 按需载入 chunks (实现方式),而不会影响到 initial chunks (html文件同步加载的script tag),因为更改initial chunks将会影响到HTML文件引入的的script tags。
webpack将会按照以下规则进行代码切割:
- 新chunk可被公用,或者是从
node_modules引入的模块 - 新chunk大于30kb(在 打包压缩 + 服务器压缩 之前)(此条意在平衡新增一次网络请求与公共代码的长缓存的利弊,可配置)
- 对于按需加载的模块,数量不能超出5个
- 对于同步入口chunks,数量不能超出3个(不新增过多的初始网络请求数,可配置)
# Configuration
webpack提供一些可配置项来满足开发者更多定制化的要求。
默认的配置项在我们看来是适合浏览器表现的最好方式,但是对你的项目来说可能会有所差异。如果你尝试覆盖默认项,请确认你的这些配置对于项目来说真的有优化作用。
# optimization.splitChunks
以下是SplitChunksPlugin的默认配置:
webpack.config.js
module.exports = {
//...
optimization: {
splitChunks: {
chunks: 'async', // 仅提取按需载入的module
minSize: 30000, // 提取出的新chunk在两次压缩(打包压缩和服务器压缩)之前要大于30kb
maxSize: 0, // 提取出的新chunk在两次压缩之前要小于多少kb,默认为0,即不做限制
minChunks: 1, // 被提取的chunk最少需要被多少chunks共同引入
maxAsyncRequests: 5, // 最大按需载入chunks提取数
maxInitialRequests: 3, // 最大初始同步chunks提取数
automaticNameDelimiter: '~', // 默认的命名规则(使用~进行连接)
name: true,
cacheGroups: { // 缓存组配置,默认有vendors和default
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
}
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# splitChunks.automaticNameDelimiter
string
webpack默认使用 origin~chunkName 的形式生成name(例如:index~detail.js)。该选项可以自定义连接符。
# splitChunks.chunks
function (chunk) | string
该选项决定优化哪些chunks。如果值为string,有三个可选项:all、async和initial。
设置为all表现会更强大,这样会使公共chunks可能同时被同步和异步引入。
webpack.config.js
module.exports = {
//...
optimization: {
splitChunks: {
// 包含所有chunks
chunks: 'all'
}
}
};
2
3
4
5
6
7
8
9
你也可以通过一个function来更精确的进行chunks控制。返回值就是需要优化的chunks。
module.exports = {
//...
optimization: {
splitChunks: {
chunks (chunk) {
// 返回所有不是`my-excluded-chunk`的chunks
return chunk.name !== 'my-excluded-chunk';
}
}
}
};
2
3
4
5
6
7
8
9
10
11
你可以配合HtmlWebpackPlugin,把提取到的公共chunks注入到html页面中(HtmlWebpackPlugin的 chunks 配置项)。
# splitChunks.maxAsyncRequest
number
按需载入的最大请求数。
译注:如果按照着配置规则,最终提取出的按需载入chunks数量大于该配置项,则优先级较低的多余chunks不会被分割成公共chunks(通常是取符合数量的size较大的几个)。
# splitChunks.maxIntialRequests
number
单个入口文件的最大请求数。
译注:如果按照着配置规则,最终提取出的初始载入chunks数量大于该配置项,则优先级较低的多余chunks不会被分割成公共chunks(通常是取符合数量的size较大的几个)。 需要注意的是,入口chunk + 默认缓存组的vendors配置项 + 默认缓存组的default配置项,这就已经是3个了,如果自定义的缓存组配置无效,注意查证该配置。
# splitChunks.minChunks
number
提取出来的chunk最小共用数量。
# splitChunks.minSize
number
提取出来的chunk需要满足的最小size,单位是bytes。
# splitChunks.maxSize
number
maxSize项(无论是全局的optimization.splitChunks.maxSize还是每个缓存组内的optimization.splitChunks.cacheGroups[x].maxSize,
或者缓存组回调optimization.splitChunks.fallbackCacheGroup.maxSize)会尝试对大于该值的chunks分割为更小的几部分。
每部分需要大于minSize的值。该算法是固定的,并且模块的改变仅会造成局部影响。所以在使用缓存组并且不需要记录时,可以使用该选项。
如果切割结果不符合minSize要求,maxSize不会生效。
如果该chunk已经有了一个name,分割出的每个chunk都会有一个新名字。optimization.splitChunks.hidePathInfo项会使分割项根据原始chunk的name派生出一个hash值。
maxSize项意在HTTP/2和长缓存中通过增加网络请求数来达到更好的缓存效果。它也可以通过减少文件体积来加快构建速度。
maxSize比maxInitialRequest/maxAsyncRequests有更高的优先级。优先级顺序为maxInitialRequest/maxAsyncRequests < maxSize < minSize。
译:官方解释的比较绕,但是其实仔细读几遍,结合理解他提到的其他配置项,会觉得说的很清楚了。这个配置项默认为0,也就是不做限制。如果做了限制,并且提取出来的chunk大于该限制,那么会把这个chunk按照minSize的规则作二次拆分,并且最终拆分出的chunks数量优先级要大于按需载入/初始载入的最大限制数量。
# splitChunks.name
boolean: true | function (module) | string
提取出来的chunk name。设置为true会根据chunks和缓存组的key来自动命名。设置为string或者function来确定你想要的命名。如果name和入口文件name相同,入口文件将被移除。
module.exports = {
//...
optimization: {
splitChunks: {
name (module) {
// generate a chunk name...
return; //...
}
}
}
};
2
3
4
5
6
7
8
9
10
11
如果给不同的spilt chunk分配相同的name( 译:按照缓存组内的filename配置来理解比较好 ),所有的依赖项都将被打包进同一个公共chunk。如果你希望提取出不同的chunks,不要这么做。
# splitChunks.cacheGroups
缓存组的配置项会继承splitChunks.*的配置,但是test,priority和reuseExistingChunk只能在缓存组中配置。 如果不需要默认的缓存组,设置为false(这个很重要) 。
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
default: false
}
}
}
};
2
3
4
5
6
7
8
9
10
# splitChunks.cacheGroups.priority
number
如果可能出现一个module同时符合多个缓存组的配置规则,你需要设置优先级,该module会被提取进优先级更高的缓存组配置项内。默认有个负数的优先级。
# splitChunks.cacheGroups.{cacheGroup}.reuseExistingChunk
boolean
如果当前chunk包含的模块已经打包进主bundle,将不再被打包进当前chunk。该配置项这会影响到chunk name。
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
vendors: {
reuseExistingChunk: true
}
}
}
}
};
2
3
4
5
6
7
8
9
10
11
12
# splitChunks.cacheGroups.{cacheGroup}.test
function (module, chunk) | RegExp | string
module的匹配规则。默认会对所有模块进行优化。你可以对module的绝对路径或者chunk name做匹配。如果匹配到一个chunk name,它的所有子模块都会被尝试提取。
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
vendors: {
test (module, chunks) {
//...
return module.type === 'javascript/auto';
}
}
}
}
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# splitChunks.cacheGroups.{cacheGroup}.filename
string
配置提取出的chunk name。output.filename的命名规则在这里也适用。
该选项也可以通过
splitChunks.filename全局配置,但是我们不建议这么做,因为如果splitChunks.chunks没有设置为initial,有可能引发报错。
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
vendors: {
filename: '[name].bundle.js'
}
}
}
}
};
2
3
4
5
6
7
8
9
10
11
12
# splitChunks.cacheGroups.{cacheGroup}.enforce
boolean: false
强制提取符合该缓存组策略的modules,并且忽略splitChunks.minSize、splitChunks.minChunks、splitChunks.maxAsyncRequests和splitChunks.maxInitialRequests配置项。
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
vendors: {
enforce: true
}
}
}
}
};
2
3
4
5
6
7
8
9
10
11
12
# 配置详情
了解了splitChunks(公共代码分离)的配置信息,下面我们就来在我们的项目中实践一下。
首先,查看package.json文件,确保你的dependencies字段内仅包含vue,vue-router,lodash三个包文件。也就是
我们的项目目前只依赖这三个包文件。如果我们不做任何配置的话,webpack会把所有的文件打包进一个文件中,如下所示:
接下来,让我们配置下将lodash文件从主文件中剥离,同时vue和vue-router打包进同一文件中。
module.exports = {
optimization: {
// 分离公共chunk在vendor文件中
splitChunks: {
chunks: 'all', // 仅提取按需载入的module
minSize: 10, // 提取出的新chunk在两次压缩(打包压缩和服务器压缩)之前要大于30kb
maxSize: 0, // 提取出的新chunk在两次压缩之前要小于多少kb,默认为0,即不做限制
minChunks: 1, // 被提取的chunk最少需要被多少chunks共同引入
maxAsyncRequests: 5, // 最大按需载入chunks提取数
maxInitialRequests: 6, // 最大初始同步chunks提取数
automaticNameDelimiter: '-', // 默认的命名规则(使用~进行连接)
name: true,
cacheGroups: { // 缓存组配置,默认有vendors和default
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
},
lodash: {
test: /lodash/,
priority: -1,
name: 'lodash'
},
vue: {
test: /vue/,
priority: 10,
name: 'vue'
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
注意这里要修改maxInitialRequests字段,因为我们配置了4个chunk,而该字段的默认值为3,已经超出了默认范围,所以webpack会
默认将其余的都打包进主文件app.js中,故这里我们尽可能的加大这个数值,以防止意外发生。
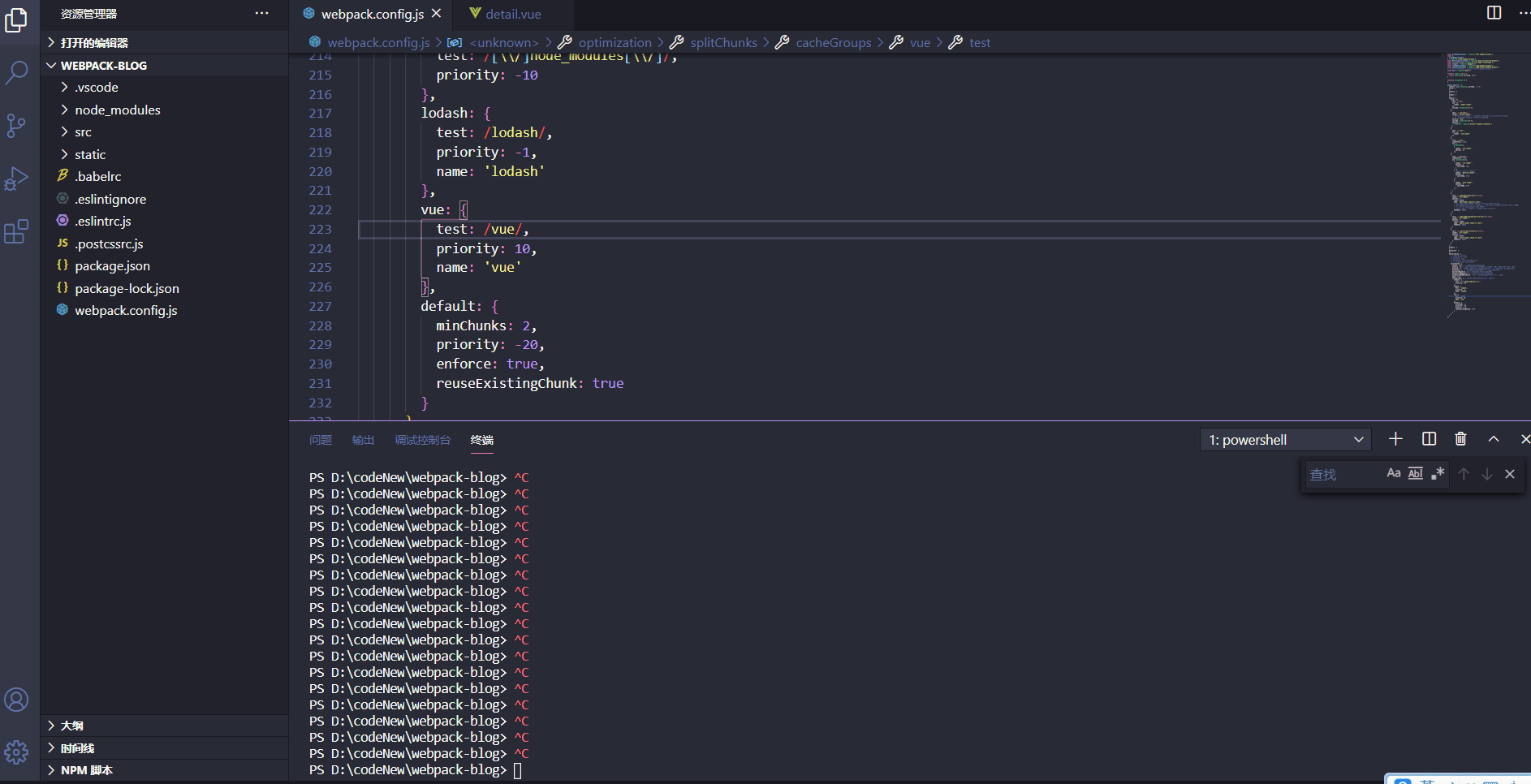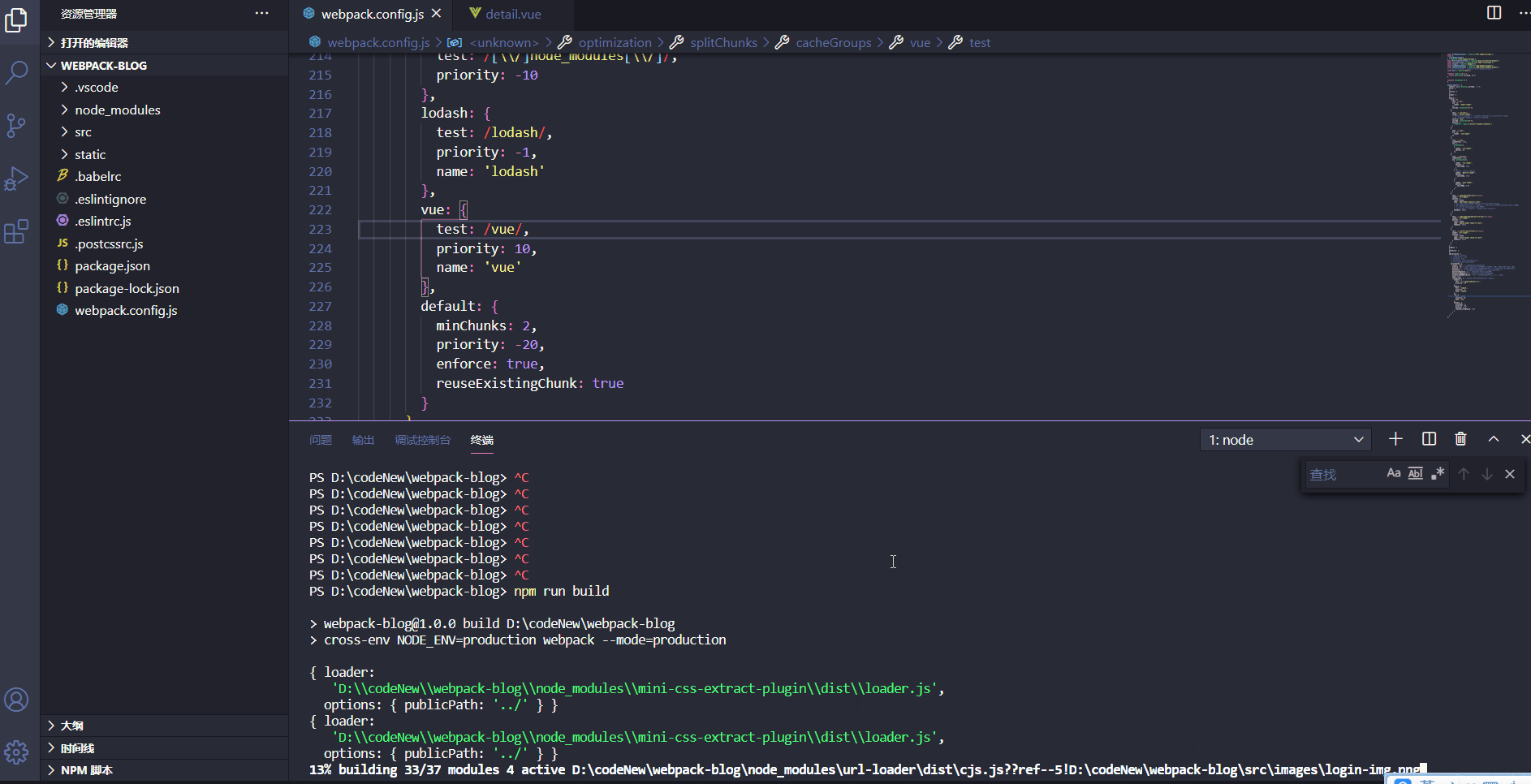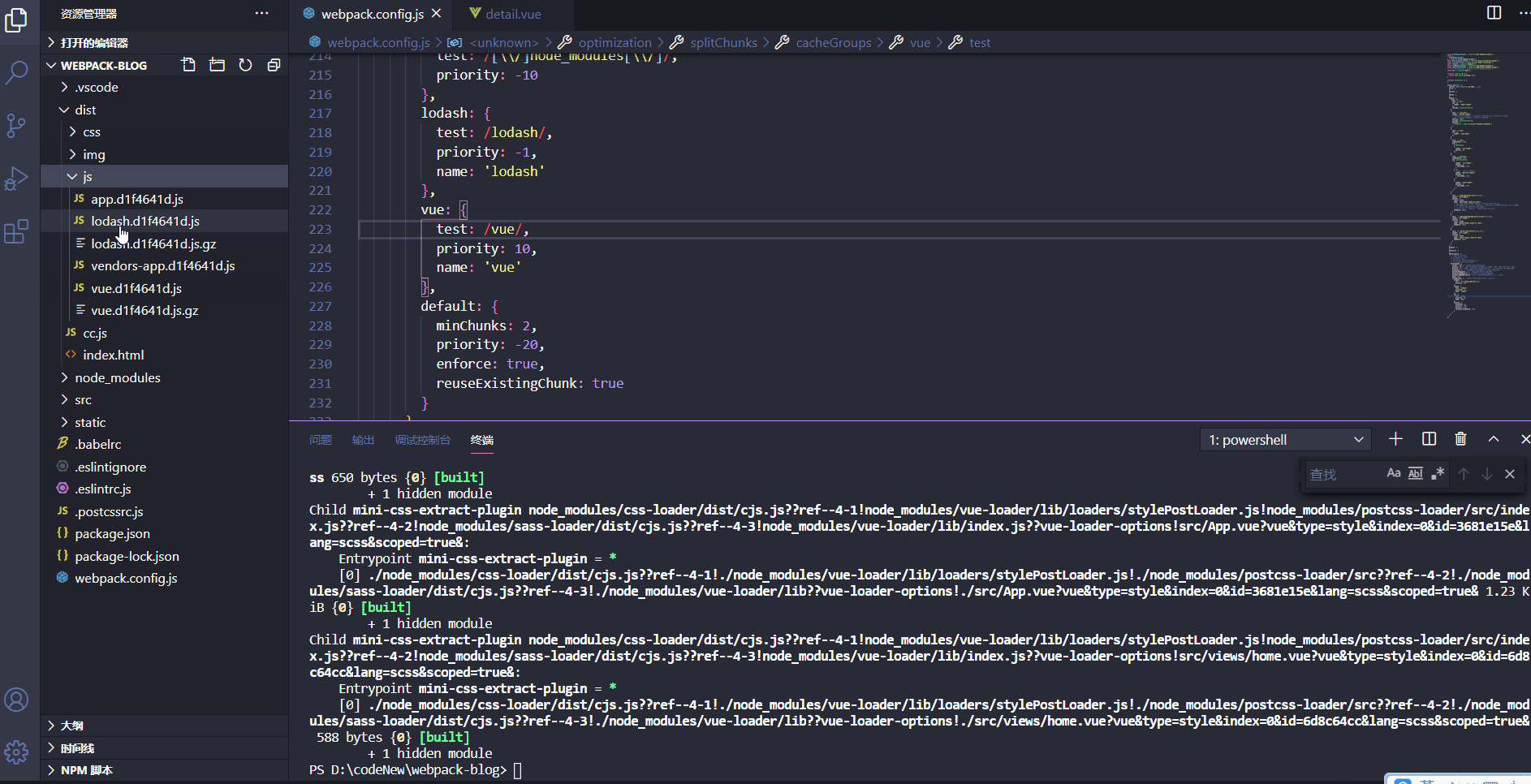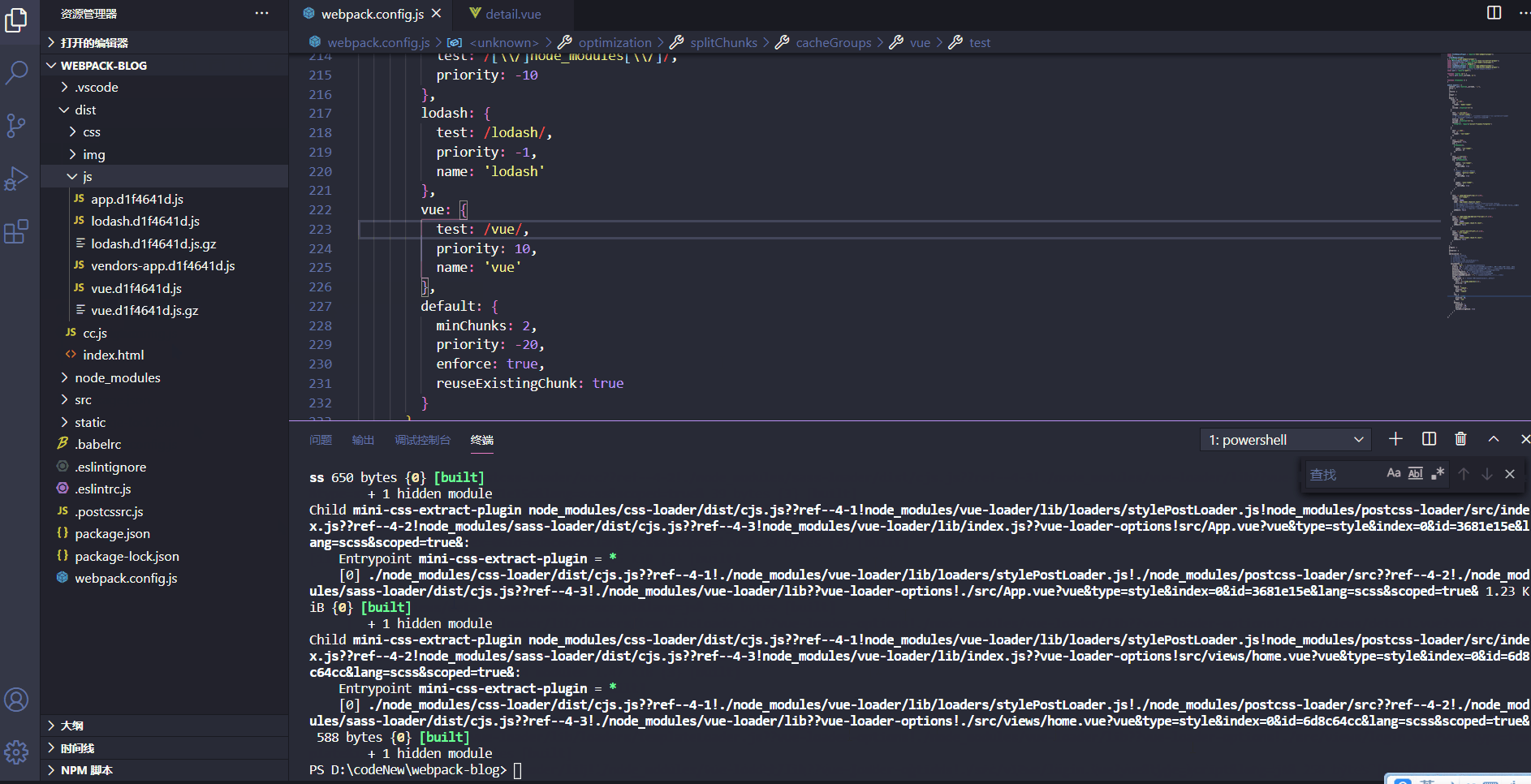
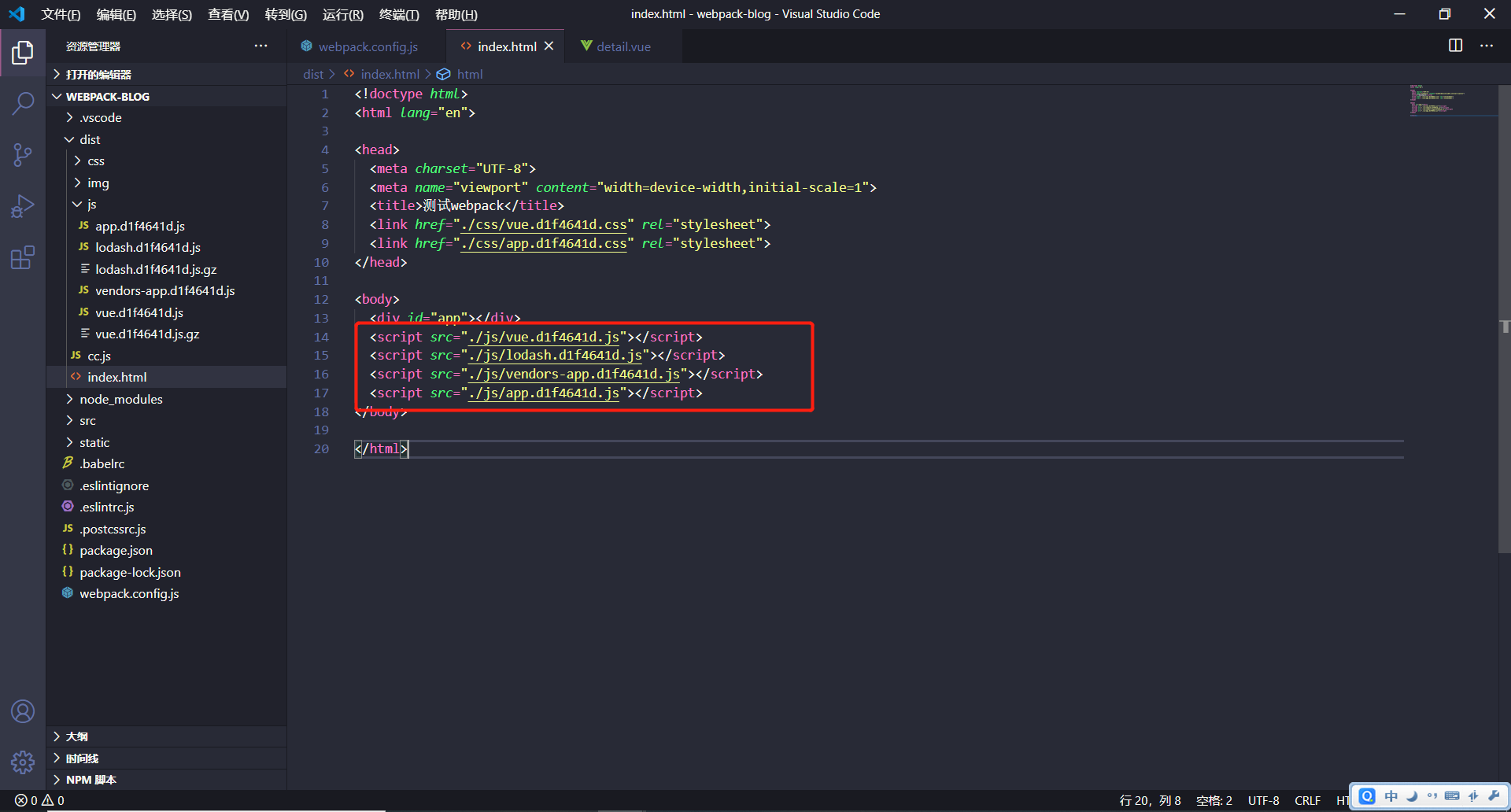
我们可以发现,根据我们的配置正常生成了vue、lodash、vender等文件,符合打包预期。
注意这里的priority选项,上面说了,这个顺序决定了打包的优先级,同时,这个值也决定了在最终生成的html文件中,
生成的js文件的引用顺序。
# 总结
将打包后的文件分离,可以有效的减少最终打包文件的体积,同时,也应该考虑,增加一次网络请求与将代码放在一个文件中的 利弊,根据实际情况配置如何分离文件才能达到优化项目加载的目的。
稍等,我们不难发现,我们只用到了lodash的一个工具函数,但是webpack却帮我们把整个lodash库都打包进项目中了,这是非常没有必要的, 要是有一种方法能帮助我们只把我们用到的函数打包进项目,那项目的体积将会进一步减小,有没有这样的方法呢,答案是有的,请关注下一节 的内容tree-shaking。